


AI inventions and sufficiency of disclosure - when enough is enough
This chapter will explore the disclosing of AI inventions, particularly in view of the requirement that a patent application discloses an invention in sufficient detail for a skilled person to work that invention. Where this chapter talks about ‘sufficiency of disclosure’, the meaning of the term found in Article 83 of the European Patent Convention (EPC) and related case law is intended. For the United States, similar requirements apply.
Overview of AI technologies
It is important to distinguish between different forms of AI, since sufficiency of disclosure is not equally relevant to every form. This chapter will follow the overview of AI in Goodfellow, Bengio and Courville’s Deep Learning (MIT Press, 2016), as illustrated in Figure 1. On the outside, a generic AI example is formed by knowledge bases (also known as ‘expert systems’), which is essentially a storage of data and a set of rules to draw logical conclusions from this data. Both the data and the rules must be supplied by the operators of the AI.
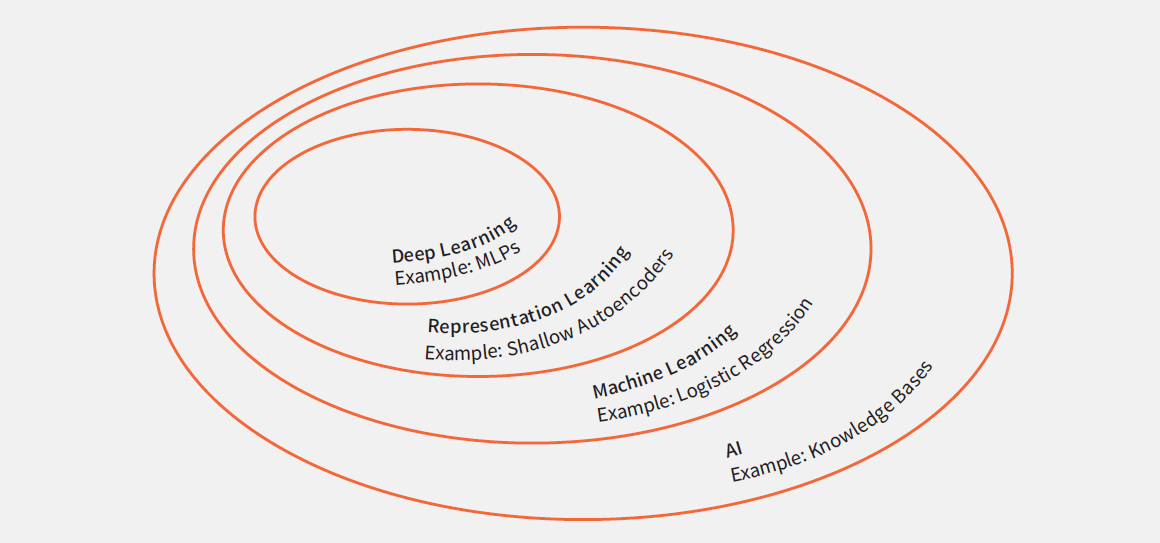
The next level is machine learning, in which the AI will use input and output data presented by an operator and will try to find a rule (eg, using logistic regression) which maps the input data to the output data, so that it can start making predictions for input data for which no output data is available. The procedure of finding a rule is typically called ‘training’ and the used data is known as ‘training data’.
Next in sophistication is ‘representation learning’, which is a specific form of machine learning. Compared to the logistic regression example above, the AI now also learns to transform the input data into a form better suited for the specific problem at hand. This is vital when the data becomes more unstructured. For example, suppose an AI model should be trained to recognise if a digital image shows a cat or a dog. Without representation learning, a team of specialists would be needed for this task: a biologist to list key physiological differences between cats and dogs; a graphical artist to draw these physiological differences in various aspects (eg, seen from front, back and side); a mathematician to design a means to calculate the degree of matching the drawings to the pixels in the digital image; and a programmer to program the matching algorithm. The contribution of the machine learning, devising a rule to resolve the detected match values into a binary cat-or-dog output, would be a relatively minor feat.
This article has been published in IAM Yearbook 2020.

